2-10 谈CS的自学 - 知乎
date_saved: 2023-08-01 12:20:57
date_published: 2018-07-01 12:25:00
Full Content:
CS与其他专业有两个巨大的不同点:
第一,CS专业读书和练习,与工作内容是相关程度是最高的。比如很多文科专业,书本上的理论在工作后是完全用不到的。而CS专业学习的东西,工作后至少70%以上是能用到或是间接需要的;
第二,CS的知识和技能,主要是依靠自学而不是学院、大学获得的。比如很多专业如数理化,自己在家研究和实验的,俗称民科,是讽刺性的;唯独CS没人讽刺民科,因为这是正确的学习和提升方法。
第一条说明了在CS专业,踏踏实实地好好学习,就必然有光明的前景,因为行业需求和工作性质所决定的;
第二条是本文的主体:一个极其大但非常现实的问题:如何自学。
这两条基础,决定了改行CS的可能性——因为实用,所以学习内容可以很快转化成工作机会;因为可以自学,所以能力不会被学院、大学所垄断。——假设你学造汽车的、射火箭的,离开大学和研究机构无疑是如何努力都只是外行和爱好者,但CS不是,CS是极少数仅仅凭借搜索引擎就可以不断自我成长的行业。
为什么要强调自学?
简单来说,因为CS:
(1)有着庞大的知识体系;任何课程和学位没法完全涵盖,所以只能依靠自学来补充;
(2)有着非常快速的进化速度;很多传统工科近一个世纪没有太多本质发展(内燃机效率只提高了70%,过去100年间),但CS几乎是每10年不到都会开启一个新时代,导致知识折旧非常快,必须依靠自学来追赶;
(3)CS的工作内容很现实和繁琐,最重视操作,但简单明快,非常适合自学,而传统的教学方式相对低效;
某种程度上来说,自学能力体现了一个程序员的基本生存能力。
假设程序员有三个级别:
(1)码畜(没有贬义,我是跟知乎人学的,你们教我的),基本没有自学能力,只能依靠同事和他人手把手教,非常依赖于文档,否则无法工作,完全不明白原理,把工作当成黑盒;
(2)码农,有一定的技术基础,在固定的技术栈中有很强的能力,了解business logic,了解原理,有自学能力,但一旦接触新环境和陌生技术容易缓慢迟钝,适应性弱;
(3)码工,有完整优异的自学能力和可扩充的知识体系,可以在短时间内学习和掌握任何技术任何系统任何产品,可以仅仅靠搜索引擎就能自我学习以及完成大量工作,效率高;
那么除了平台、资质、机遇这些因素外,我觉得最区分的就是自学能力。
自学的难度是一开始最高,后面逐渐下降。这个很好理解:越是新手,越糊涂,知道的东西越少,越没有整体感和判断力——随着慢慢成长,知道的东西越来越多,可以轻松判断很多技术的本质和要点,所以自学越来越容易。
本文先谈谈从零开始的自学,对新人最重要。
不要过多地纠缠于理论
知乎上有很多关于CS书籍的问题,推荐了很多经典书目,这里不再罗列,请自己找寻。我为什么不列呢,是因为经典书太多,改行者根本看不完,每个方面选一本最经典的足够了。
依我看,完全依赖读书,是低效率的做法。因为CS的核心是操作,而不是理论,所以难度根本不在读书上。我在自己学习的早期,也曾读过很多书,包括操作系统的原理等,发现的确受益匪浅——但,并不能很快转化为利益,这就不是高效率的方法。
西方一直有种思想,即:“科研是不缺吃喝的贵族所从事的”,我非常同意,还在担心吃喝的人,最好去当学徒、手艺人、商人、海员或是士兵先。具体思路就是快速变现(变成工作机遇),用行业术语说就是追求Conversion(转化)。
回到CS,就是“在面对非必要性的知识时,如果想钻研,一定确保自己已经衣食无忧”。比如操作系统内核是怎样的,比如硬件部分,比如编译原理等。这里肯定有科班出身的专家跳出来说编译原理如何如何有用他工作中可能每天接触等,的确,我今天也不会,因为没时间去补充这方面的知识——即使有时间,我也更愿意投入到Distributed System这些内容中我觉得意义和作用更大。但至少这并不很影响我在技术和职业上的成长。
这是因为,软件行业已经不是一般的复杂和巨大。每个人,哪怕是一个领域的专家,看到的也都只是一小部分,不过是盲人摸象罢了。所以,对于技术和知识,要学通用的、流行的,要针对面试,要大胆舍弃一些重要但并不实用的知识,“地毯式轰炸”、“打破砂锅问到底”式的学习虽然精神可敬,但效率并不划算。
所以,了解基本原理即可,不必深究。
我推荐的新手学习方法
有人指责我不该否认读书的作用。我没有否认读书,我只是降低了读书的比例,个人认为读书应该占30%-40%的比重,而不是更高。
新手的最大特点是:什么都不懂、笨、容易放弃、效率低、没人领。那么,我个人认为,应该从简单、实际、容易理解的角度入手,强调操作,即按照以下步骤:
(1)读书——了解最基本的理论;
(2)上机——立刻上机编程实现刚学过的内容(假设可以的话);
(3)记忆和复述——基于理论和程序,自己复述刚才学到的内容;
好,我就演示给你们看,如何重复这个过程。
举例:(这是一道面试经典和常用题,知识性的,难度很低)Java中,什么是String Immutable?(这里有人可能说我不会Java和Java的String,请花一点点时间下载Eclipse等IDE,设置基本环境,花一点点时间了解一下最基本的Java运行和debug,什么是String、String的基本操作等,如果走到这里都有困难,建议不要改CS了,太难)。
(1)读书——理论和定义部分。
An immutable object means that the object cannot change its value (because it is not allowed by the programming language implicitly).
Source: Why is string immutable?
(注:这个问题因为实在太简单,所以我就随便找了个Source)
(注2:因为习惯问题,我使用的多是英文材料,不习惯者可以搜baidu “string immutable”然后看中文内容,下同)
这句话读起来非常简单:不允许改变值,编程语言是implicitly、也就是暗示、没有明说地禁止了改变值的行为。String Immutable自然是说Java中String的值不能够被改变。
好像很简单,但不明白?那就对了,这就是我认为读书和理论最多只占30%-40%的原因。因为这个问题,其实定义和说明是完全没必要的,直接搜例子更容易理解:
(2)上机:
其实这段简单程序说明了一切:
public class StringExamples
{
public static void main(String[] args)
{
String s1 = "JAVA";
String s2 = "JAVA";
System.out.println(s1 == s2); //Output : true
s1 = s1 + "J2EE";
System.out.println(s1 == s2); //Output : false
}
} Source:http://javaconceptoftheday.com/example-to-prove-strings-are-immutable/
看不懂的话我来解释:
第一个要点,s1和s2是两个分别定义的String,内容一样,正常情况应该拥有不同的地址,但code中测试他们所指向的引用和地址,竟然是一样的,所以第一个output是true。这个说明是什么呢?细想一下就知道,说明只有一个“JAVA”被创建了,有些人不知道这个。因为字面上Immutable可没说这事儿,字面和理论上只说string不能改,可没说_所有声明的同值的string们都share同一个copy对吧_?——所以,上机才能理解真实情况。
第二个要点,s1和s2指向同一个“JAVA”基础上,一旦改变s1的值,则s1和s2不再相等,这是因为“JAVA“这个string是不允许改变的,那么s1的值改变了,它就要自己创建新的值然后指向新的值,所以s1、s2不再相等。
(3)记忆和复述
其实这段程序说明的事情用图表达更简单:
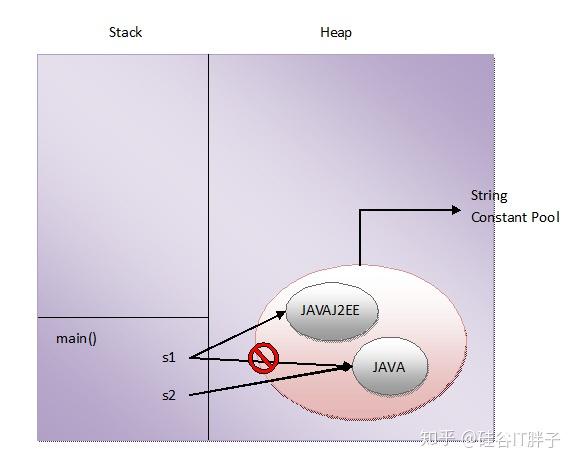
来源同上:http://javaconceptoftheday.com/example-to-prove-strings-are-immutable/
所以当你解释Java String Immutable给别人的时候,如果头脑中有这个图,和这几行简单至极的代码,就清楚多了,英文定义是怎么说,完全不关键了。英文常说“一图顶千言”,这图还有很多额外信息:Java的string是存在一个叫做“String Constant Pool”的东西(即使你不知道这是什么,暂时地)里面的,而这个东西在Heap中。
所以,这个简单的例子我想说明的是,我的推荐的学习方法是:
任何一件事情,一个理论,一个事实,都(最好)需要有一段简单程序加上一个示意图来证明和演示。
比如,数组的内存地址是连续的,链表不是,如何证明?打印地址然后比较即可,还趁机加强了初学者对内存地址的理解;有人说这么简单的东西也需要证明?我只是展示思维方法;
比如,多线程很复杂,如何演示其产生、运行、等待、结束?网上有例子,每个线程输出打印自己的状态即可。就可以简单地让读者看清楚每一步发生了什么;
然而这只是初学者所能掌握的。当略有基础后,可以开始以此为中心扩展,虽然有点偏题(因为本意只是想演示初学者如何用实际例子学习)。
接下来可以扩展思考(以下部分新手可能不能理解全部):
- 为什么有String Immutable这种设计?可能的答案:Thread Safe;Security;提升HashMap的performance(cache hashcode);
- String Immutable对Performance有什么影响、现实中什么情况下不能用string?可能的答案:因为改变会不断重新构建,所以在loop中频繁改变一个string其实是不断地重新创建,所以perfomance会很差;
- 接续2,那么频繁操作string怎么办?可能的答案:用StringBuilder;
- 接续3,StringBuilder内部是如何实现的?可能的答案:char[],参考: https://www.thecodingdelight.com/java-stringbuilder-class/
- 对刷题有何作用?可能的答案:一旦涉及String频繁改动,用StringBuilder,不要偷懒,这是个很能区分新手和有经验的工程师的一个小细节;
所以,小小的一个”String Immutable”话题,足可以引申出非常多的话题,如果这些话题都懂了或是至少涉猎过,那么想必面试中被问到这个话题,不会只干巴巴地说定义,而是能扯上至少5分钟。
所以,回到主题,再重复一遍我所推荐的学习方法:
(1)读书,不要过于纠结其定义和内容,但要理解其基本含义;
(2)上机,用一段最简单的code证明和演示;
(3)记忆和复述,试想假设是面试,或是你给别人讲这个问题,如何说清楚?
**(4)扩展(optional,需要一定的基础,早期可跳过),(工程中)为什么这么做?原因是什么?背景是什么?现实中基于这个事实的有哪些?**以String Immutable为例,就会涉及到内存管理,HashMap的实现、缓存和性能,多线程,网络传输和数据库连接等很多不那么简单的话题了。
这种学习方法最好之处在于,入手之处非常小,而且简单,一个个小话题而已;但因为有实际例子相伴,所以不需要死记硬背,能够帮人真正理解,很适合基础差、资质低的人逐步掌握技术的全貌。即使很长时间后,完全忘记了定义,但能想到图和程序,也大概可以说清楚。
尤其是中后期了解的东西越来越多时,扩展部分就会越来越丰富和深入,逐渐把整个知识体系串联在一起,不断的回顾和触碰,有利于自身知识体系的融合和重整。比如本文的例子,既然涉及到string存在哪里,就可以回顾内存管理的内容——Binary Code存在哪里了,数据存在哪里等。
有人可能会质疑:比如CPU、Scheduler那些你怎么直接用程序证明?这个当然很难,尤其是底层的东西,所以应该舍去或是仅仅学习理论即可;但是比如什么是Process,好多人只看定义,其实不如从command line直接启动记事本(最简单的例子,notepad.exe, 后面也可以带参数),然后打开任务管理器,就对Process的启动、性能和属性(比如PID)有了很直观的认识,再在command line查找并输出之,最后从command line执行命令kill掉它——这个操作过程也涉及了一些东西的。
归根结底,CS是实践性学科,所有其理论和做法,都是以现实为基础的。与其花费时间理解理论,不如理论与现实相结合。
额外的参考资料:https://www.programcreek.com/2013/04/why-string-is-immutable-in-java/
Highlights
CS与其他专业有两个巨大的不同点:
第一,CS专业读书和练习,与工作内容是相关程度是最高的。比如很多文科专业,书本上的理论在工作后是完全用不到的。而CS专业学习的东西,工作后至少70%以上是能用到或是间接需要的;
第二,CS的知识和技能,主要是依靠自学而不是学院、大学获得的 ⤴️
第一条说明了在CS专业,踏踏实实地好好学习,就必然有光明的前景,因为行业需求和工作性质所决定的;
第二条是本文的主体:一个极其大但非常现实的问题:如何自学。 ⤴️
为什么要强调自学?
简单来说,因为CS:
(1)有着庞大的知识体系;任何课程和学位没法完全涵盖,所以只能依靠自学来补充;
(2)有着非常快速的进化速度;很多传统工科近一个世纪没有太多本质发展(内燃机效率只提高了70%,过去100年间),但CS几乎是每10年不到都会开启一个新时代,导致知识折旧非常快,必须依靠自学来追赶;
(3)CS的工作内容很现实和繁琐,最重视操作,但简单明快,非常适合自学,而传统的教学方式相对低效;
某种程度上来说,自学能力体现了一个程序员的基本生存能力。
假设程序员有三个级别:
(1)码畜(没有贬义,我是跟知乎人学的,你们教我的),基本没有自学能力,只能依靠同事和他人手把手教,非常依赖于文档,否则无法工作,完全不明白原理,把工作当成黑盒;
(2)码农,有一定的技术基础,在固定的技术栈中有很强的能力,了解business logic,了解原理,有自学能力,但一旦接触新环境和陌生技术容易缓慢迟钝,适应性弱;
(3)码工,有完整优异的自学能力和可扩充的知识体系,可以在短时间内学习和掌握任何技术任何系统任何产品,可以仅仅靠搜索引擎就能自我学习以及完成大量工作,效率高; ⤴️
自学的难度是一开始最高,后面逐渐下降。这个很好理解:越是新手,越糊涂,知道的东西越少,越没有整体感和判断力——随着慢慢成长,知道的东西越来越多,可以轻松判断很多技术的本质和要点,所以自学越来越容易 ⤴️
本文先谈谈从零开始的自学,对新人最重要。 ⤴️
依我看,完全依赖读书,是低效率的做法。因为CS的核心是操作,而不是理论,所以难度根本不在读书上。我在自己学习的早期,也曾读过很多书,包括操作系统的原理等,发现的确受益匪浅——但,并不能很快转化为利益,这就不是高效率的方法 ⤴️
西方一直有种思想,即:“科研是不缺吃喝的贵族所从事的”,我非常同意,还在担心吃喝的人,最好去当学徒、手艺人、商人、海员或是士兵先。具体思路就是快速变现(变成工作机遇),用行业术语说就是追求Conversion(转化 ⤴️
回到CS,就是“在面对非必要性的知识时,如果想钻研,一定确保自己已经衣食无忧”。比如操作系统内核是怎样的,比如硬件部分,比如编译原理等 ⤴️
我今天也不会,因为没时间去补充这方面的知识——即使有时间,我也更愿意投入到Distributed System这些内容中我觉得意义和作用更大。但至少这并不很影响我在技术和职业上的成长。
这是因为,软件行业已经不是一般的复杂和巨大。每个人,哪怕是一个领域的专家,看到的也都只是一小部分,不过是盲人摸象罢了。所以,对于技术和知识,要学通用的、流行的,要针对面试,要大胆舍弃一些重要但并不实用的知识,“地毯式轰炸”、“打破砂锅问到底”式的学习虽然精神可敬,但效率并不划算。 ⤴️
了解基本原理即可,不必深究。 ⤴️
新手的最大特点是:什么都不懂、笨、容易放弃、效率低、没人领。那么,我个人认为,应该从简单、实际、容易理解的角度入手,强调操作,即按照以下步骤:
(1)读书——了解最基本的理论;
(2)上机——立刻上机编程实现刚学过的内容(假设可以的话);
(3)记忆和复述——基于理论和程序,自己复述刚才学到的内容; ⤴️
英文常说“一图顶千言” ⤴️
所以,这个简单的例子我想说明的是,我的推荐的学习方法是:
任何一件事情,一个理论,一个事实,都(最好)需要有一段简单程序加上一个示意图来证明和演示 ⤴️
所以,回到主题,再重复一遍我所推荐的学习方法:
(1)读书,不要过于纠结其定义和内容,但要理解其基本含义;
(2)上机,用一段最简单的code证明和演示;
(3)记忆和复述,试想假设是面试,或是你给别人讲这个问题,如何说清楚?
(4)扩展(optional,需要一定的基础,早期可跳过),(工程中)为什么这么做?原因是什么?背景是什么?现实中基于这个事实的有哪些 ⤴️
归根结底,CS是实践性学科,所有其理论和做法,都是以现实为基础的。与其花费时间理解理论,不如理论与现实相结合。 ⤴️